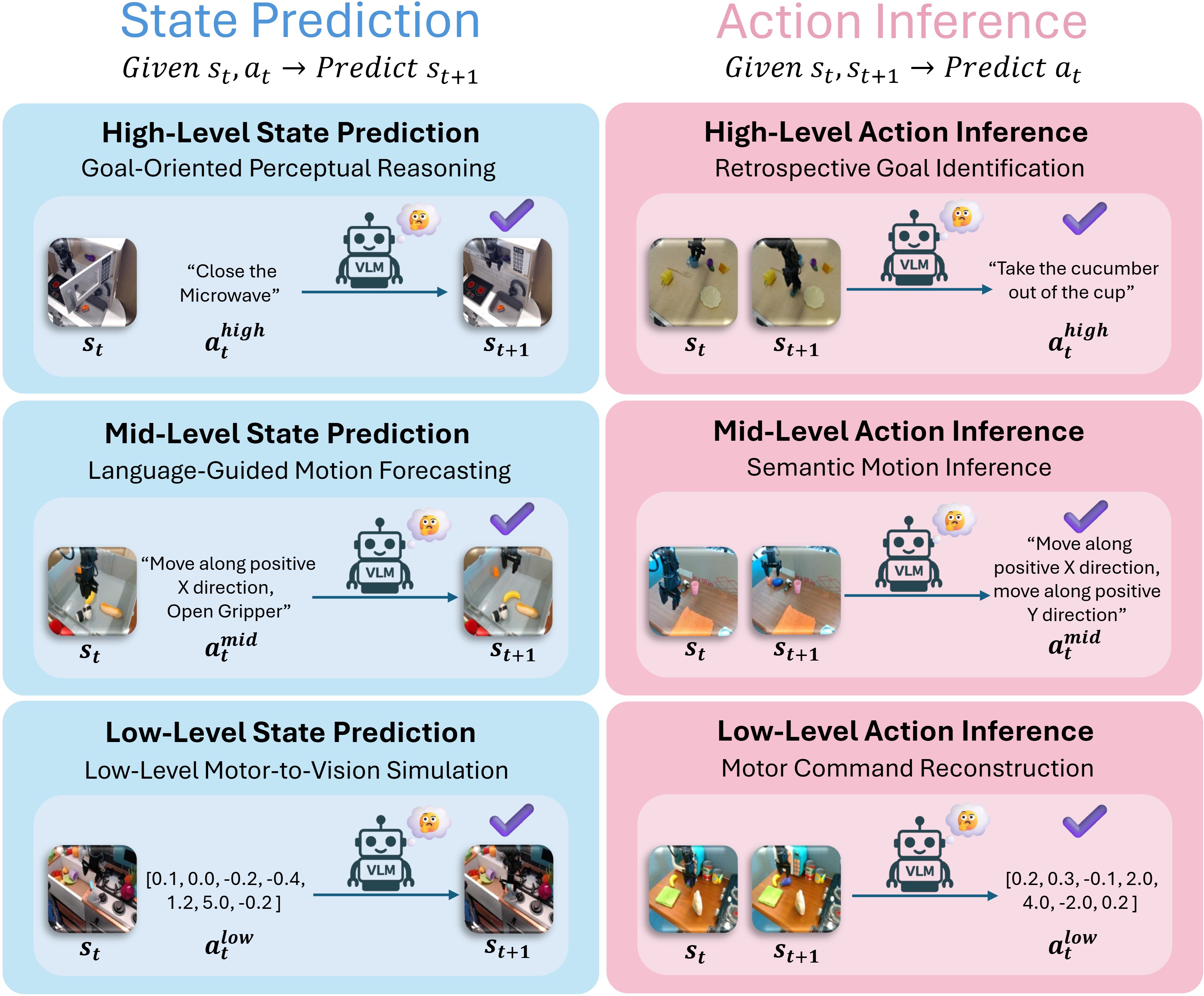
ActionEQA's bidirectional framework exposes a striking asymmetry in VLM reasoning: models find it systematically easier to infer what action caused an observed outcome (Action Inference) than to predict the visual result of a planned action (State Prediction).
This gap is statistically significant across all 34 evaluated models (p < 0.001, paired t-test), with Action Inference outperforming State Prediction by an average of 4.31 pp. The top model, Gemini-2.5-Pro, shows the largest absolute gap: 63.7% AI vs. 53.2% SP — a 10.5 pp deficit in forward predictive reasoning.
This pattern reveals a fundamental weakness: current VLMs are better at retrospective explanation than prospective prediction of physical dynamics. Interestingly, humans exhibit the opposite trend — slightly better at SP — suggesting that predictive physical simulation is a distinctly human cognitive strength.